There is a common assumption among founders who have done their homework: if GPTBot is crawling my site and my content is indexed, I should be appearing in AI recommendations. When ChatGPT still does not mention their startup, the confusion is understandable.
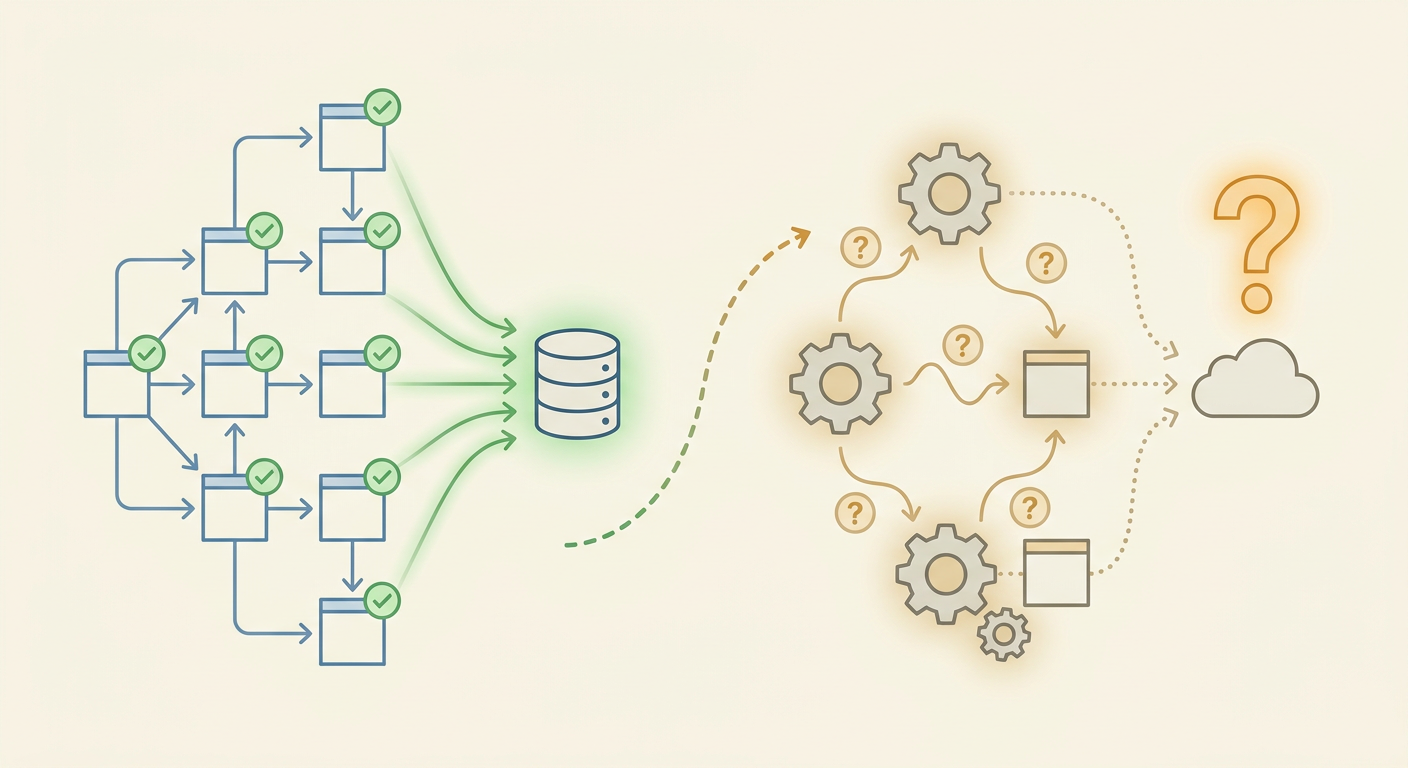
Crawlability and recommendation confidence are two completely separate problems. A site can be fully crawlable, fully indexed, and completely absent from AI-generated recommendations. Understanding why requires understanding how AI recommendation systems actually work.
Two separate systems
AI crawlers collect content. AI recommendation systems evaluate confidence. Satisfying the first system does not satisfy the second. Most startup visibility problems live in the gap between them.
What AI Crawling Actually Does
When GPTBot, ClaudeBot, or PerplexityBot crawls your site, it is performing a specific job: collecting text content to be used in training data or real-time retrieval. The crawler reads your HTML, extracts the text, and makes it available to the underlying model. That is the entire job of the crawler.
Crawling does not evaluate quality. It does not assess whether your content is clear, consistent, or trustworthy. It does not compare your content against competitors. It does not form a view on whether your brand is recommendation-worthy. It simply collects text.
This is why checking your robots.txt for crawler access is necessary but nowhere near sufficient. Confirming GPTBot can access your site solves the crawlability problem. It does not touch the recommendation confidence problem.
Crawlability baseline checks
- robots.txt does not block GPTBot, ClaudeBot, PerplexityBot, or Bingbot
- Core pages are server-rendered with static HTML, not JavaScript-only
- No meta robots noindex tags on key pages
- Sitemap.xml is present and linked in robots.txt
- Pages load and return 200 status without requiring authentication
What Recommendation Confidence Actually Requires
Recommendation confidence is the probability that an AI system surfaces your brand when a relevant query arrives. It is determined by a different set of signals entirely.
The AI system is asking itself a more demanding question than "does this page exist?" It is asking: "Do I understand this brand clearly enough to confidently recommend it to someone who is evaluating their options?" The answer depends on entity clarity, semantic consistency, and ecosystem reinforcement.
Entity clarity: does the AI know what you are?
Entity clarity is the precision of the category model the AI has formed about your brand. A clear entity model means the AI can confidently answer: this company makes X for Y users who want to achieve Z. An unclear entity model means the AI has indexed content but cannot form a precise, confident description.
Weak entity clarity is usually the result of ambiguous homepage copy, inconsistent category language across pages, or metaphorical positioning that the AI cannot decode into a specific category. A site can be fully crawled and produce a completely ambiguous entity model.
Semantic consistency: does your own site agree with itself?
If your homepage calls your product one thing but your About page calls it something different and your pricing page uses a third description, the AI must reconcile conflicting signals from a single source. Inconsistency within your own site is one of the fastest ways to undermine recommendation confidence.
Ecosystem reinforcement: does the broader web confirm the model?
Even if your own site is perfectly clear and consistent, recommendation confidence requires external reinforcement. AI systems treat their entity model as more reliable when multiple trusted external sources confirm the same description. Press coverage, directory listings, product reviews, user discussions, and third-party mentions all contribute.
A brand that exists only on its own website, with no external ecosystem, faces a structural confidence ceiling regardless of how well-optimized that website is. The AI system has no corroborating evidence. Recommendation confidence remains low even with full crawl access and excellent internal consistency.
Ecosystem isolation is a confidence ceiling
If your brand has no meaningful external mentions, your recommendation confidence is structurally limited. Crawl access does not resolve ecosystem isolation. Only building genuine external presence does.
The Gap Between Crawled and Recommended
Crawlability vs recommendation confidence requirements
| Requirement | Crawlability | Recommendation confidence |
|---|---|---|
| robots.txt access | Required | Prerequisite only |
| Server-rendered HTML | Required | Prerequisite only |
| Content indexed | Sufficient | Necessary but not sufficient |
| Entity clarity | Not evaluated | Required |
| Semantic consistency | Not evaluated | Required |
| External ecosystem | Not evaluated | Required for durable confidence |
| Structured data | Not evaluated | Strongly reinforces confidence |
Founders who optimize only for crawlability are solving the wrong problem. Crawlability is the floor, not the ceiling. Recommendation confidence is the actual target.
How Structured Data Bridges the Gap
Structured data in JSON-LD format is one of the most direct ways to close the distance between crawled and recommended. Structured data makes explicit declarations that the AI system can process without inference.
An Organization schema block declares your brand name, your category, your description, and your official URL in a machine-readable format. A Product schema block declares what you offer. A FAQ schema block provides explicit question-answer pairs. Each of these removes inference from the equation and substitutes direct extraction.
What to Do After Confirming Crawl Access
Once you have confirmed that AI crawlers can access your site, the next priority is not more technical optimization. It is signal quality.
Recommendation confidence improvement priorities
- Rewrite homepage H1 and subheadline to state category, user type, and outcome explicitly
- Ensure consistent category language across homepage, About, Features, and Pricing pages
- Add JSON-LD Organization and Product schema to core pages
- Build a FAQ section that defines your category boundaries explicitly
- Audit all external directory listings for description accuracy and consistency
- Begin earning third-party mentions that use your canonical category description
The AudFlo recommendation readiness audit evaluates all of these dimensions in a single analysis, identifying which gaps are creating the most recommendation hesitation. If you want to understand what a complete audit looks like, see a sample audit report.
Being indexed is table stakes. Being recommended requires the AI to trust what it found. Those are different problems requiring different solutions.
Matt Lin, AudFlo
Frequently Asked Questions
If GPTBot is crawling my site, why does ChatGPT not know about my brand?
Crawling and knowing are different things. GPTBot collects your text content. Whether ChatGPT forms a confident, accurate understanding of your brand depends on the quality and consistency of that text, and on what external sources say about you. A crawled page with ambiguous copy contributes minimal recommendation confidence.
Does blocking AI crawlers hurt recommendation confidence?
Yes, significantly. If you block GPTBot, ClaudeBot, or PerplexityBot in your robots.txt, those systems cannot access your content for training or retrieval. Blocking crawlers removes you from the potential recommendation pool entirely. The first step is always ensuring access is permitted.
Can JavaScript-rendered pages be crawled by AI systems?
Most AI crawlers do not execute JavaScript. If your content only appears after JavaScript runs, crawlers see an empty or near-empty page. This makes server-rendering or static HTML generation a prerequisite for AI visibility, not just a performance optimization.
What is the fastest way to improve recommendation confidence after solving crawlability?
The fastest lever is improving entity clarity on your homepage, specifically rewriting the H1, subheadline, and first paragraph to state your category, user type, and outcome directly. This affects browse-time recommendation accuracy immediately and training-time accuracy at the next update cycle.
How does ecosystem reinforcement help if my site is already crawled?
AI systems treat entity models as more reliable when multiple independent sources confirm the same description. Your website is one source. When press coverage, directories, reviews, and community discussions use consistent language to describe your brand, the AI gains confidence that its model is accurate and becomes more willing to recommend you.