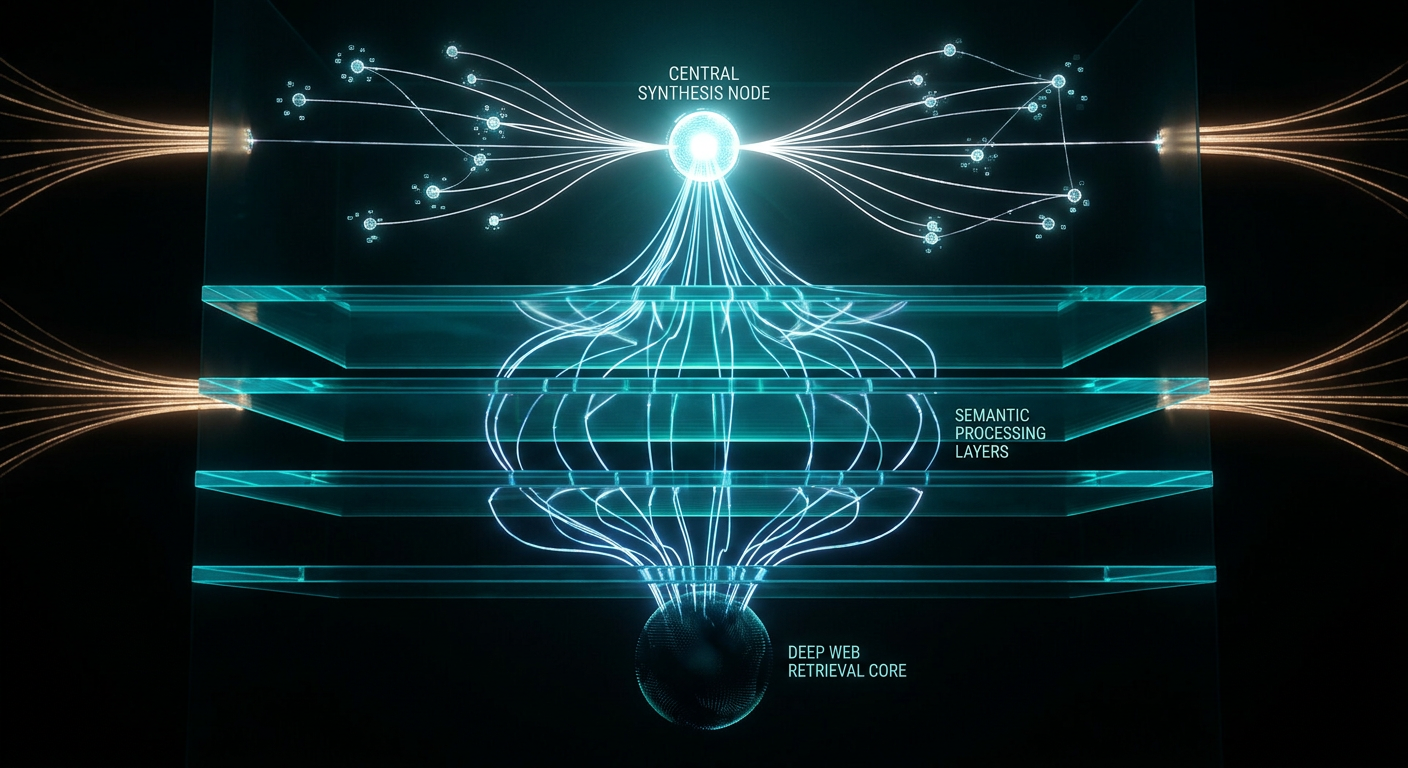
Most people assume ChatGPT simply "knows" information. That is only partially true. Modern ChatGPT operates through a combination of training data, real-time retrieval systems, semantic scoring, and probabilistic synthesis. Training data creates foundational entity associations built up during model training. Retrieval systems supplement that with real-time web content at query time. Understanding how these two systems interact is the most important foundation for AI visibility strategy. Brands that appear only in one system but not the other have significant blind spots in their citation probability.
Where this fits in the cluster
This article is a deep dive sitting beneath the AI search platforms overview. If you have not read the platform comparison yet, start with the AI search platforms guide for context on how ChatGPT compares to Google, Perplexity, and AI Mode.
How ChatGPT Actually Retrieves Information
ChatGPT operates using two major information systems: training data and retrieval systems.
Training data is the foundational knowledge learned during model training. This includes websites, articles, books, forums, PDFs, public datasets, transcripts, documentation, and conversations across the internet. This training creates deep patterns and associations inside the model.
For example: if enough trusted sources repeatedly connect a brand with a specific topic, the AI increasingly learns that association during training. That association then influences future retrieval and generation behavior.
But training data alone is not enough. Because the internet changes constantly. New companies launch, new products ship, new research publishes. Training data becomes outdated. This is why retrieval systems became critically important.
Training Data vs Real-Time Retrieval
Training data is static. It represents a snapshot of information captured during training periods. This creates real limitations: outdated information, missing recent events, missing new companies, and incomplete freshness.
To solve this, modern AI systems increasingly rely on retrieval systems. Retrieval systems allow the AI to search the web, retrieve recent sources, gather contextual information, and synthesize updated answers in real time.
Training data vs retrieval systems
| Dimension | Training data | Retrieval systems |
|---|---|---|
| When formed | Fixed at training time | Dynamic at query time |
| Freshness | Degrades over time | Current as of retrieval |
| Coverage | Broad but bounded | Targeted but real-time |
| Influence on output | Entity associations, patterns | Specific citations and facts |
| Founder leverage | Build mentions before training cutoff | Build retrievable content now |
| Optimization target | Brand consistency across sources | Crawlable, structured, semantic content |
This means visibility now depends heavily on retrievability, discoverability, semantic relevance, and contextual associations. Founders who focus only on ranking pages are missing the retrieval dimension entirely.
What Is Retrieval Augmented Generation?
Retrieval Augmented Generation, commonly called RAG, is one of the most important systems powering modern AI search experiences.
RAG works by combining language model intelligence, external retrieval systems, live information gathering, and contextual synthesis. Instead of generating answers purely from training memory, the model actively retrieves fresh information and uses it to inform the response.
The RAG retrieval pipeline (simplified)
- User enters a prompt into the AI interface
- AI interprets the semantic intent behind the prompt
- Retrieval systems search for relevant sources across the web
- Retrieved information is ranked by relevance and authority
- AI synthesizes retrieved sources with learned model knowledge
- Final response is generated, with citations drawn from retrieved sources
This changes discoverability dramatically. The AI is no longer limited to memory alone. It actively retrieves from the web. This means SEO still matters, topical authority matters, semantic relevance matters, citations matter, and brand mentions matter.
Modern AI visibility increasingly depends on retrieval probability. This is the same mechanism that drives query fan out behavior: the AI retrieves across many semantic branches simultaneously, and brands appearing consistently across those branches gain compounding retrieval advantages.
Why ChatGPT Does Not Work Like Google
Traditional Google search historically worked around rankings. You optimized for positions, keywords, backlinks, search intent, and SERP competition. A clear rank one existed for most queries.
ChatGPT behaves differently. It does not simply rank pages. Instead, it retrieves multiple sources, evaluates semantic relationships, synthesizes information, and generates probabilistic responses.
This means there is no fixed "rank one" inside ChatGPT visibility. The same prompt may cite different websites, mention different brands, retrieve different sources, and generate different outputs across sessions.
Visibility inside ChatGPT becomes probabilistic instead of static. This is one of the biggest shifts in discoverability history, and it is why ChatGPT requires a fundamentally different optimization approach than Google, Perplexity, or any traditional search engine.
The ranking mindset is a liability in ChatGPT optimization
Founders who approach ChatGPT visibility the same way they approach Google rankings will consistently underinvest in the signals that actually matter: brand mentions, entity consistency, semantic breadth, and external publisher presence.
How ChatGPT Decides What To Cite
ChatGPT retrieval systems evaluate many signals simultaneously when determining which sources to cite and which brands to mention.
Semantic Relevance
How contextually relevant the content is to the query intent. This goes beyond keyword matching. A page that comprehensively covers a topic concept is more semantically relevant than a page that simply mentions the keywords.
Topical Authority
How consistently the brand appears across related topics. A brand with comprehensive coverage across an entire topic cluster carries stronger topical authority than a brand with a single well-ranked page.
Consensus Across Sources
Whether multiple trusted sources reinforce similar information. When Wikipedia, Forbes, Reddit, and several niche publications all describe a brand similarly, the AI gains confidence in that description. Consensus is a reliability signal that influences citation frequency.
Freshness and Authority Signals
Whether the information appears current and relevant. Trusted publishers and credible sources carry stronger retrieval confidence. A mention in Wired carries more entity weight than a mention in an unknown blog, because the authority signal compounds the association.
Entity Relationships
Repeated associations between brands and topics strengthen future retrieval probability. This is the compounding mechanism at the core of ChatGPT visibility strategy.
Why Brand Mentions Matter So Much
One of the most misunderstood concepts in AI visibility is this: mentions often matter more than direct backlinks for ChatGPT specifically.
Why? Because AI systems learn through repeated association. If your brand repeatedly appears alongside concepts like AI visibility, SEO, retrieval systems, AEO, and semantic search, the AI increasingly associates your entity with those concepts.
This creates stronger retrieval confidence over time. Even when the AI does not directly cite your website URL, repeated mentions still shape semantic understanding, entity confidence, and future visibility probability.
Visibility compounds through repetition. This is the same principle that makes AI visibility compound faster than traditional SEO: each new association reinforces the existing ones, creating a progressively stronger retrieval signal over time.
Where to earn mentions that influence ChatGPT
Prioritize Wikipedia, trusted industry publications, Reddit, high-authority review sites, and editorial media. These are the source categories ChatGPT weighs most heavily. Your own website matters far less for ChatGPT than your presence across credible external sources.
Why AI Visibility Is Probabilistic
Traditional SEO conditioned marketers to think in rankings. AI systems do not behave that way.
ChatGPT outputs are probabilistic. This means retrieval varies, citations vary, outputs vary, and visibility varies. The same prompt asked multiple times may produce different citations, different examples, and different recommendations.
This is because AI systems combine retrieval probabilities, semantic scoring, contextual weighting, and generation variability. The result is a range of possible outputs, not a fixed set.
This fundamentally changes optimization strategy. You are no longer chasing one ranking position. You are increasing retrieval probability across an ecosystem so that your brand appears frequently across the range of possible outputs.
How to think about probabilistic visibility
Instead of asking "do I rank for this keyword?", ask "how often does my brand appear when AI responds to this category of questions?" Visibility frequency across many similar prompts is a far more useful measure than any single retrieval instance.
How Semantic Retrieval Changes SEO
Modern discoverability increasingly rewards topic ecosystems, semantic breadth, entity consistency, contextual relationships, and repeated associations.
This means topical authority matters more, supporting content matters more, semantic depth matters more, and multi-platform visibility matters more.
A single landing page is rarely enough anymore. The strongest AI visibility strategies build pillar content, supporting articles, semantic clusters, FAQs, glossary pages, discussion visibility, and publisher mentions.
AI systems increasingly retrieve from semantic ecosystems instead of isolated pages. This is the structural reason query fan out rewards comprehensive topic coverage: the AI fans out across a topic and finds your brand repeatedly, which compounds the retrieval confidence.
Signals that increase ChatGPT retrieval probability
- Brand mentions across high-authority publications, Reddit, and Wikipedia
- Consistent entity descriptions across multiple external sources
- Comprehensive topic cluster coverage on your own site
- FAQ and structured content formats that AI can extract answers from
- Clear schema markup establishing entity type, name, and description
- Presence in trusted review and comparison sites within your category
- Crawlable HTML content that renders before JavaScript execution
- Topical depth across an entire cluster rather than a single optimized page
What Founders Should Do Differently
Founders should stop thinking only about rankings, backlinks, and isolated pages. The optimization mindset needs to shift toward retrieval probability, entity visibility, semantic associations, discoverability ecosystems, topic reinforcement, and citation opportunities.
The brands winning AI visibility today are repeatedly discussed, contextually reinforced, semantically associated, and broadly retrievable. Visibility increasingly behaves like memory reinforcement. The more often your brand appears across trusted contexts, the stronger retrieval probability becomes.
The practical first step is understanding where you currently stand. An AI visibility audit reveals which topics your brand is currently associated with inside AI retrieval systems, where the semantic gaps are, and which signals most need strengthening.
Understanding Retrieval Is The Competitive Advantage
ChatGPT retrieval systems fundamentally change discoverability. The future is no longer static rankings, isolated pages, or single keyword optimization.
Modern AI visibility revolves around semantic relevance, retrieval systems, topical ecosystems, entity consistency, and probabilistic visibility.
The brands that understand retrieval infrastructure early gain disproportionate advantages. Because in the AI era, discoverability is increasingly determined by what AI systems remember, retrieve, and repeat.
This understanding connects back to the core principle in the AEO pillar guide: visibility in the AI era is probabilistic, semantic, and ecosystem-driven. ChatGPT is where that principle is most clearly visible in practice.
FAQ
How does ChatGPT retrieve information?
ChatGPT uses both training data and real-time retrieval systems depending on the query. Training data provides foundational knowledge and entity associations. Retrieval systems allow ChatGPT to search the web for current information, which is then synthesized into the response alongside learned knowledge.
What is Retrieval Augmented Generation?
RAG combines AI language models with real-time information retrieval systems. Instead of generating answers purely from training memory, the model retrieves fresh information from external sources and uses it to inform and ground the response. This improves factual accuracy and freshness.
Does ChatGPT search the internet?
Sometimes, depending on the system configuration and query requirements. ChatGPT with web browsing enabled actively retrieves current information. Without it, responses rely on training data. Both configurations benefit from strong entity associations and brand presence across credible external sources.
Why are brand mentions important for ChatGPT visibility?
Repeated brand mentions across trusted sources strengthen the semantic entity associations that ChatGPT uses to determine retrieval confidence. Even when the AI does not directly cite your URL, consistent mentions across authoritative sites build the entity associations that influence future retrieval frequency.
Does ChatGPT rank websites like Google does?
No. ChatGPT visibility is probabilistic rather than position-based. There is no fixed "rank one." The same prompt may surface different brands across different sessions. Optimization focuses on increasing retrieval probability across the range of possible outputs, not securing a single ranking position.
What is semantic retrieval?
Semantic retrieval focuses on meaning and contextual relevance rather than exact keyword matches. AI systems retrieve sources based on how well the content relates conceptually to the query intent, not just whether specific words appear. This rewards comprehensive topic coverage over keyword density.
Can small brands appear in ChatGPT responses?
Yes. Strong topical authority and semantic relevance can increase visibility significantly even for small brands. ChatGPT does not rely on domain authority the same way Google does. A brand with precise entity consistency and strong external mentions within a focused niche can achieve meaningful ChatGPT retrieval probability.
Does SEO still matter for ChatGPT visibility?
Yes. SEO remains foundational for retrievability. Well-structured, crawlable, semantically rich content is a prerequisite for AI retrieval. But traditional SEO alone is insufficient. ChatGPT also requires external brand presence, entity consistency, and semantic breadth that pure on-page SEO cannot provide.
Why do AI responses vary for the same prompt?
AI systems generate probabilistic outputs using retrieval probabilities, semantic scoring, contextual weighting, and generation variability. This means the same prompt produces a range of possible outputs rather than one fixed answer. Increasing retrieval probability means appearing frequently across that range.
What is the future of discoverability in AI search?
Semantic retrieval ecosystems and AI-driven visibility. Discoverability will increasingly be determined by entity associations, topical authority across comprehensive clusters, and probabilistic retrieval frequency rather than static ranking positions.