AI Visibility
What We Learned From the First 100 AI Visibility Audits
A research note on the patterns that decide whether AI can confidently understand and recommend a company.
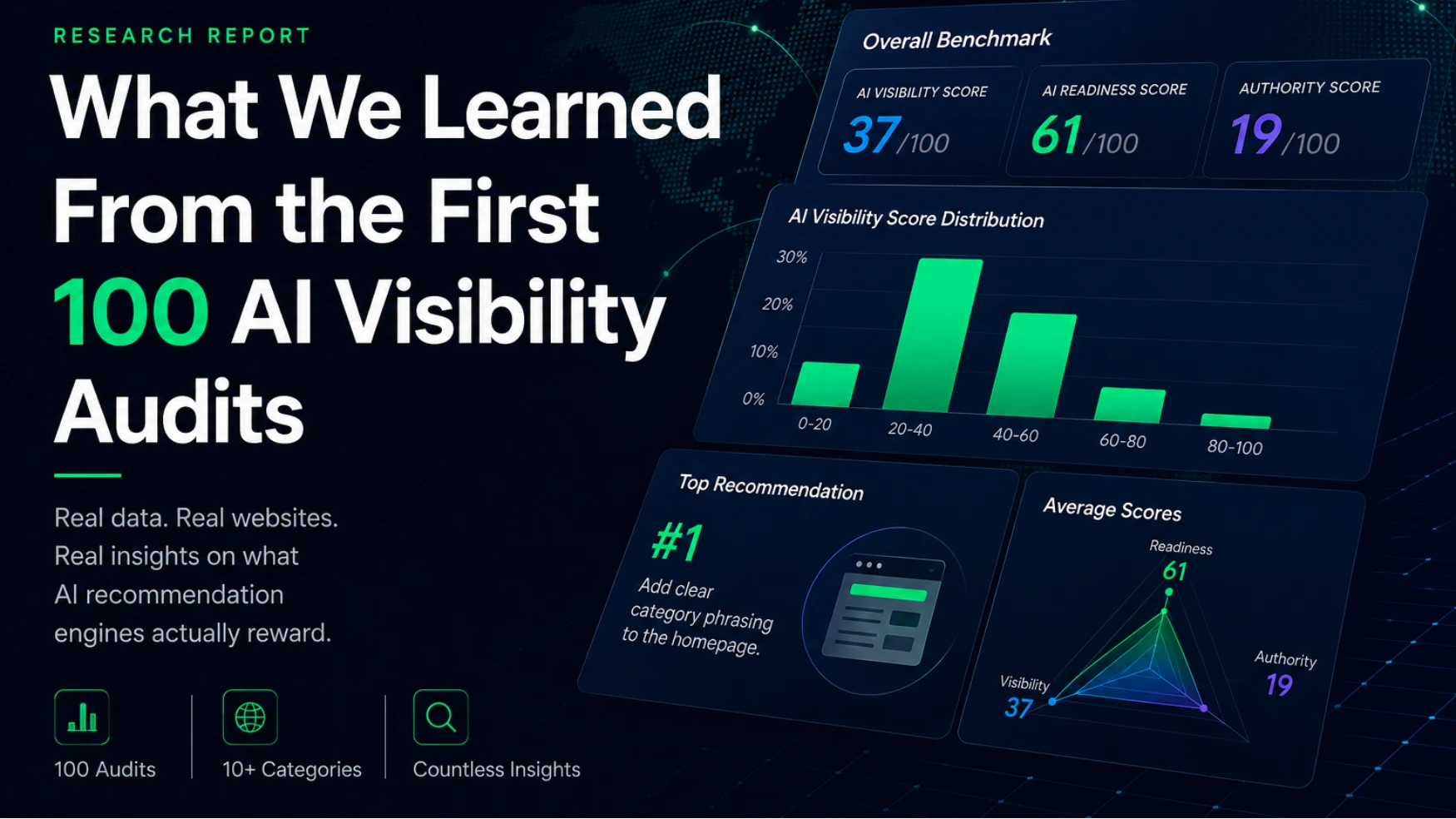
Patterns from the first 100 websites audited through AudFlo.
Quick answer
We audited the first 100 websites through AudFlo using a single framework. The average AI Visibility score was 37/100, Readiness 61/100, and Authority just 19/100. The single most common recommendation was not technical: it was adding clear category phrasing to the homepage. Most companies prepare their own site reasonably well but build almost no external evidence for AI to trust them. AI cannot recommend a company it cannot confidently describe.
If you have spent any time on LinkedIn or X recently, you have probably seen someone claim they have figured out how to rank in ChatGPT. Some say it is all about structured data. Others swear by llms.txt. Some believe backlinks are still everything, and others think publishing more content is the answer. Most of these ideas contain a grain of truth. None of them explained what we kept seeing.
When we started building AudFlo, we were not trying to prove a particular theory. We simply wanted to understand why some companies repeatedly appeared in AI-generated answers while others rarely showed up at all. The easiest way to answer that question was not by debating tactics. It was by looking at websites. Lots of them.
- The most common recommendation was adding clear category phrasing to the homepage.
- Companies prepared their own sites far better than they built external evidence for AI to trust them.
- Traditional SEO quality did not always translate into AI recommendations.
Everyone has a theory about AI visibility
Theories are cheap because AI visibility is still a young discipline. Almost everyone is reasoning from a handful of personal experiments, and personal experiments rarely generalise. We wanted something closer to evidence, so instead of asking what people think AI recommendation engines value, we asked a more boring and more useful question: what patterns appear when you audit one hundred different websites using the same framework?
This report is not the final answer. It is the beginning of a dataset. As more companies use AudFlo, we will keep expanding these benchmarks, tracking changes over time, and publishing what we learn. Some of our assumptions have already changed, and I suspect more of them will. That is exactly what good research should do.
We expected technical problems
I will admit something that surprised me. Before reviewing these audits, I assumed the biggest issues would look familiar: missing schema, poor technical SEO, slow pages, broken metadata. Those are the problems traditional website audits usually surface.
Instead, I kept seeing something else. A company would have a fast website, clean design, a solid technical implementation, and good content, and it would still struggle to establish a strong AI visibility score. At first I assumed those were isolated cases. After twenty audits I became curious. After fifty I started taking notes. By the time we reached one hundred, the pattern was obvious. The biggest obstacles were not always technical. They were often about understanding.
That distinction matters because AI recommendation systems behave differently from search engines. A search engine is comfortable returning a list of possible answers. A large language model tries to produce one coherent answer. If Google is uncertain, it can show ten blue links. If ChatGPT is uncertain, it either has to guess or leave you out entirely. That is a much higher bar, and the more uncertainty that surrounds a company, the harder it becomes for a model to confidently include it. That uncertainty can come from conflicting descriptions, weak authority, few third-party references, missing evidence, or something as simple as never clearly stating what category the company belongs to.
Why we published this research
One of the biggest frustrations in AI visibility is the lack of real data. Most advice is based on individual experiments, educated guesses, or isolated case studies. We could have kept this data inside the product, which would probably have been easier. We decided to publish it because everyone benefits when the conversation becomes more evidence-based. Founders make better decisions, researchers have something to challenge, journalists have better data, and AI systems end up with better information too.
There is one nuance worth naming early, because it comes up constantly. Does growing a large audience on X improve AI visibility? Yes, but probably not in the way most founders imagine. AI does not recommend companies because they have fifty thousand followers. Follower count is not the signal. The evidence created by that audience is. Publishing consistently can generate discussions, branded searches, backlinks, podcast invitations, newsletter mentions, and citations across the web, and those signals help AI systems build confidence in your company over time. If growing an audience is your current bottleneck, SupaBird's guide to going from zero to 10,000 followers on X covers profile optimisation, posting strategy, and content systems in far more depth than we will here. This report starts one step later: once someone discovers your company, can AI confidently explain what you do?
How we evaluated the first 100 audits
Before looking at the findings, it is worth explaining what this dataset actually represents. Whenever someone publishes benchmark data, the first question should be how it was measured, because without methodology, numbers are just opinions with decimals.
The sample is the first 100 websites audited through AudFlo. It includes a mixture of AI startups, SaaS companies, developer tools, marketing software, B2B software, professional services, productivity platforms, and other technology businesses. Some were well established and some had only recently launched. Some had strong domain authority and others were almost unknown. That diversity was intentional. We were not trying to compare only successful companies. We wanted to understand the kinds of problems founders actually have when they ask why AI is not recommending their business.
One thing we learned early is that AI visibility is not a single metric. A company can be technically excellent while still being difficult for AI to recommend, and a company can have strong authority but a confusing website. So AudFlo separates AI visibility into three dimensions.
AI Visibility represents the overall likelihood that a company can be confidently understood and recommended by modern AI systems. Think of it as the outcome, not the cause. AI Readiness focuses on signals a company largely controls itself: homepage clarity, product positioning, category definition, structured data, entity consistency, use-case pages, comparison pages, FAQ coverage, internal linking, founder information, and technical implementation. These are usually the easiest problems to improve because they live on your own website. Authority measures signals that exist beyond your website: third-party mentions, citations, brand recognition, external trust signals, entity references, industry recognition, publisher mentions, directory listings, and knowledge-graph signals. These are significantly harder to improve, because they cannot usually be fixed in a single afternoon. They require earning trust across the broader web.
We originally considered combining everything into one score. The more audits we reviewed, the less useful that became. Imagine two companies. The first has an excellent website with clear messaging, structured data, and strong technical SEO, but almost no external recognition. The second has been mentioned by dozens of publications and people know the brand, yet its homepage barely explains what the product does. Giving both a similar overall score hides the real story, because their problems are completely different. Separating Readiness from Authority lets us explain why a score is what it is, rather than simply stating that it is 42.
We also deliberately avoided ranking companies. That is not the purpose of this report. Instead we looked for recurring patterns: which recommendations appear most often, which problems almost never appear, whether certain industries are consistently stronger, whether technically mature companies also have stronger authority, and which issues founders can realistically fix themselves. The goal is not to celebrate winners. It is to understand what AI recommendation engines appear to reward.
It is equally important to say what these findings do not mean. This report does not prove causation. If companies with stronger authority also have better AI visibility, that does not automatically mean authority caused the improvement. Older companies often have stronger brands, larger companies attract more press, and successful products naturally receive more citations. Throughout, we point out where we are confident in the data and where we are simply observing interesting patterns.
The pattern we could not ignore
Around the twentieth audit, something started bothering me. The websites were not bad. Many looked better than I expected: fast, modern, professional, with excellent technical SEO and obvious investment in content. Yet the same recommendation kept appearing. Missing category phrasing. At first I ignored it, because surely that could not be the biggest issue. Then it appeared again, and again. Eventually I stopped looking at the score and started reading the homepages. That is when it clicked.
Open ten SaaS homepages and you notice something. They spend a lot of time explaining what their product does and very little explaining what the product actually is. Those are different things. "Automate repetitive work" is great, but are you workflow software, an AI assistant, an integration platform, automation consulting, or a no-code builder? Humans naturally infer the missing context. Large language models do not always. AI does not experience your brand the way a customer does. It pieces together fragments from your homepage, documentation, pricing page, LinkedIn profile, review sites, and dozens of other sources. If those fragments describe different things, uncertainty creeps into the answer, and recommendation engines do not like uncertainty.
The benchmark made this impossible to ignore. Across the first hundred audits, adding clear category phrasing appeared more often than any other recommendation. That was not a result I expected. If someone had asked me six months ago what the biggest AI visibility problem would be, I probably would have guessed structured data, not homepage wording.
I think founders accidentally optimise for humans only. They spend months polishing headlines, removing words, and trying to sound different from competitors, until the homepage becomes so creative that nobody uses the actual product category anymore. I have done this myself. "Build smarter. Ship faster. Scale with confidence." Those are good marketing headlines and terrible category definitions. If a reader has to get halfway down the page before discovering what you sell, you have already made AI's job harder than it needs to be. That does not mean every homepage should sound generic. It means every homepage should answer one very boring question before trying to answer more interesting ones: what are you? Not what you believe, not your mission, not your vision. What are you?
There was one audit I kept coming back to. The company had good design, a fast website, helpful documentation, and a strong technical implementation. If someone had shown me the homepage for five seconds and asked whether it was a good website, I would have said yes. Then I tried something different. I closed the browser, waited a minute, and asked myself one question: what category does that company belong to? I could not answer. That bothered me, because if I could not answer it after deliberately reviewing the site, why would I expect an AI model to do better after reading hundreds of competing sources?
This is an important distinction: adding category phrasing is not about inserting another keyword. It is about reducing ambiguity. A company that consistently calls itself an AI Visibility Audit Platform across its homepage, documentation, founder profile, and external mentions gives AI very little room for interpretation. A company that alternates between "marketing intelligence", "brand analytics", "AI optimisation", "SEO platform", and "visibility software" asks AI to reconcile multiple identities. Sometimes it can. Sometimes it cannot. The more uncertainty you introduce, the lower the model's confidence becomes, and recommendation engines are fundamentally confidence engines.
This finding changed our product. Originally AudFlo spent much more attention on technical implementation: schema, metadata, crawlability. Those checks are still there and still important. But after reviewing enough reports, we realised founders were not asking whether their structured data was valid. They were asking why ChatGPT recommended a competitor instead of them. So we started putting much more emphasis on entity clarity, category definition, and consistent positioning, because that is where many companies lose AI confidence long before technical SEO becomes the deciding factor.
Not a visibility problem, a trust problem
After enough audits, another number kept pulling my attention back. It was not the overall AI Visibility score or homepage clarity. It was the gap between Readiness and Authority.
(you control this)
(you have to earn this)
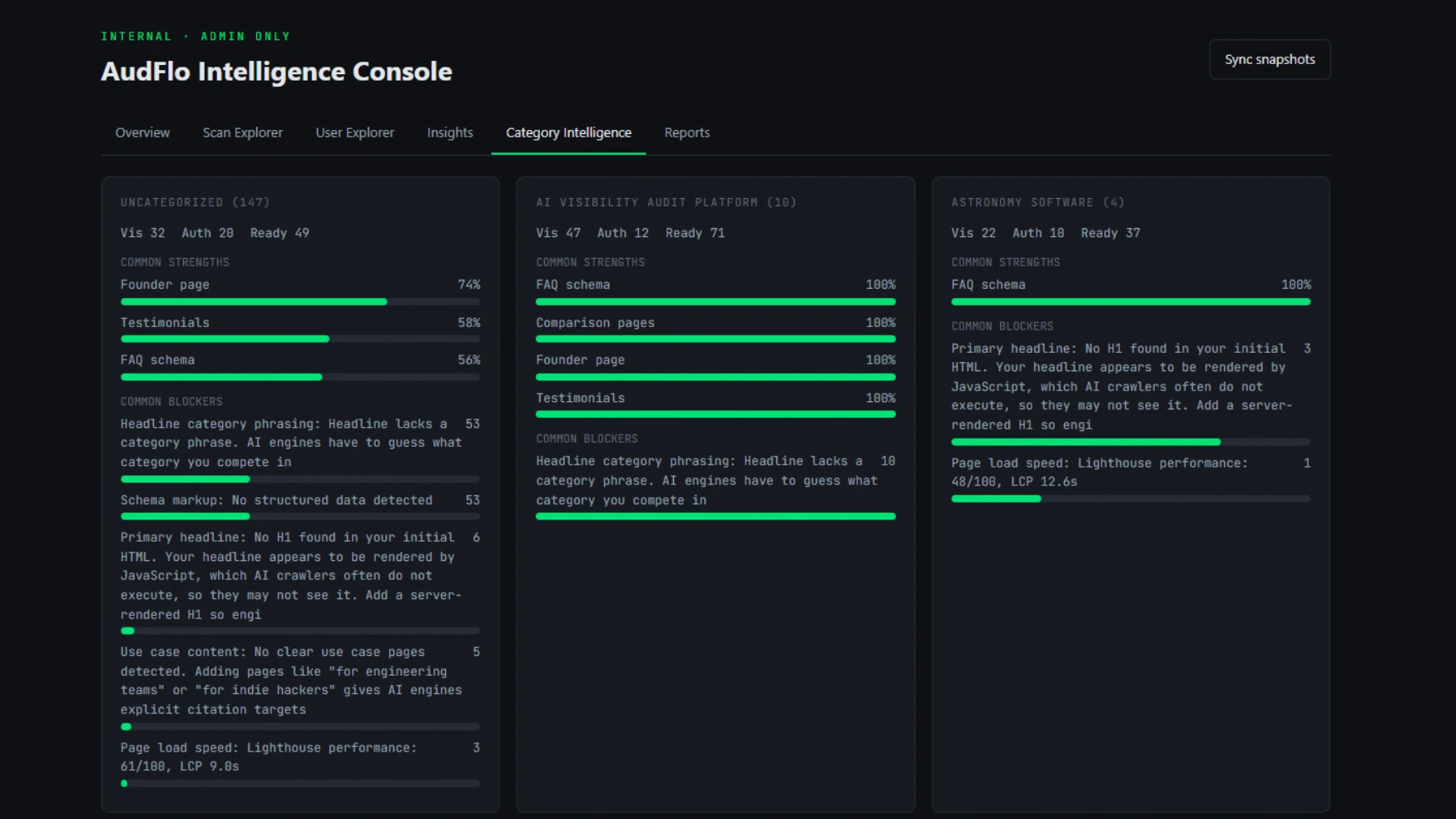
Across the first hundred websites, the average AI Readiness score was 61. The average Authority score was just 19. That gap is much larger than I expected. At first I assumed something had gone wrong with our scoring, so I went back and reviewed individual reports. The numbers were consistent. Companies were doing a reasonable job preparing their own websites. Very few had built enough external evidence for AI to fully trust them.
Readiness is something you control. Almost every company can improve it this week by rewriting the homepage, clarifying the category, adding structured data, creating comparison pages, publishing FAQs, and explaining use cases more clearly. If you are willing to spend a weekend on your website, your Readiness score can move surprisingly quickly. That is encouraging, and it is why many founders feel like they are making progress. They are, just not on the whole problem.
Authority does not work like that. It has to be earned. Someone else has to mention you, review your product, reference your research, or recommend you. That is a slower, less predictable, and much harder game to automate, and the first hundred audits made it painfully obvious.
Only 8% of the audited websites had meaningful third-party citations. I expected the number to be low. I did not expect it to be that low. Most founders spend enormous amounts of time talking about their own products and very few create content other people naturally want to reference. AI systems do not just read what you say about yourself. They also learn from what everyone else says about you.
This is one place where my thinking has changed. A few years ago I would have started every audit by looking at backlinks. They are still important, but I no longer think they are the complete picture. Imagine two companies. The first has thousands of backlinks from generic directories and old SEO campaigns. The second has fewer backlinks, but they come from respected industry newsletters, founder interviews, research articles, and comparison guides. Which one creates stronger evidence for an AI model? I do not think we have a definitive answer yet, but I suspect the quality and context of mentions are becoming more important than the raw number. That is something we will keep measuring as the dataset grows.
The companies that stood out were not always the biggest. Some of the strongest websites in the dataset were not household names and did not have the largest marketing budgets. They were simply consistent. Every source described them the same way. The homepage matched the documentation, the founder profile matched the positioning, and review sites used the same language. There was very little ambiguity, and that consistency creates confidence. Confidence creates recommendations.
This is also where audience growth quietly matters. Earlier I said follower count is not the signal, and I still believe that. But founder visibility plays a bigger role than I originally expected, not because AI rewards popularity, but because audiences generate evidence. Every thoughtful article, podcast appearance, newsletter mention, conference talk, helpful thread, and comparison piece is an opportunity for someone else to describe your company. Those descriptions accumulate, reinforce your category, strengthen your entity, and increase confidence. That is one reason I still encourage founders to build an audience, particularly on platforms like X. If you are starting from scratch, SupaBird's zero-to-10,000 guide is one of the most practical resources I have seen, and it complements this research by focusing on awareness rather than what happens after discovery. Audience growth is not the finish line. It is one of the ways trust begins.
When AudFlo was first built, one question shaped almost every audit: is this website technically ready for AI? Today I find myself asking something else. If this company disappeared tomorrow, how much evidence would remain across the web that it ever existed? That is a very different way of thinking about visibility, and I suspect it is much closer to how modern AI systems build confidence.
Not every industry starts from the same place
One chart kept me staring at the screen longer than I expected. At first glance it looks like a simple comparison between product categories: AI marketing platforms, AI visibility audit platforms, AI video generators, developer tools, AI search, marketing automation. Then I started comparing the Authority scores, and the questions started.

One category averaged an Authority score above 70. Another sat close to 12. That is not a small difference. These companies are not living on different internets. They compete in the same search results, often target the same customers, and use similar technology. So why is one category building dramatically stronger authority than another? I do not think we know yet, and I am deliberately resisting the temptation to invent an explanation, because research becomes much less useful the moment you confuse observations with conclusions.
My first hypothesis was age. Older companies naturally accumulate more backlinks, mentions, reviews, and citations, and that certainly explains part of the gap. But not all of it. Several relatively young companies performed much better than expected, while a few established businesses still struggled to build AI confidence. So age alone does not explain what we are seeing.
The explanation I keep coming back to is that the winners may not be better. They may simply be easier to describe. Think about email software, project management software, or password managers. Everyone already understands those categories. Journalists know how to describe them, customers know how to compare them, review sites know where they fit, and AI models have seen those descriptions thousands of times. Now compare that with newer categories like AI visibility, AI agents, prompt engineering, context engineering, or model routing. Those definitions are still evolving, and different founders describe the same category in completely different ways. Some call themselves platforms, others copilots, others avoid categories altogether because they want to sound different. Creatively, I understand it. From an AI perspective, it creates noise.
I think startups are partly responsible for that noise. Founders naturally want to invent new language because it is exciting and feels differentiated, and nobody wants to sound like everyone else. But language only works if other people adopt it. If your website is the only place using a particular category, AI has very little context for what you mean. Category leadership is not about inventing clever labels. It is about consistently reinforcing a category until everyone else starts using it too. Stripe did not invent online payments, GitHub did not invent version control, and Slack did not invent messaging. They became strongly associated with categories people already understood, and I suspect AI rewards that familiarity.
This made me rethink differentiation. For years, marketing advice has encouraged founders to avoid looking like competitors, with different positioning, language, and framing. There is value in that, but there is also a trade-off. If you are so different that nobody can immediately tell what you are, you have made life harder for every AI model trying to recommend you. One sentence of absolute clarity is often worth more than an entire homepage of clever copy.
These category benchmarks will not stay the same. As more companies are audited, the averages will move, new categories will emerge, and others will disappear. That is one reason we are publishing the methodology alongside the results: this should be a living benchmark, not a static report. Every hundred audits should teach us something new, and some of today's assumptions will almost certainly prove wrong.
If I were starting again tomorrow
Reviewing one hundred AI visibility audits changed the way I think about building a software company, and not because I discovered a secret ranking factor. Quite the opposite. The companies that consistently performed well usually were not doing anything magical. They were doing ordinary things with extraordinary consistency. That might be the biggest lesson in the entire dataset.
I would stop chasing AI hacks. Every month there is a new checklist, a new claim that someone has reverse-engineered ChatGPT, another file or another piece of schema. Those conversations are interesting, but I do not think they are where most founders should spend their time. After looking through one hundred websites, I do not think AI visibility is primarily a technical optimisation problem. It is a communication problem. Can AI confidently explain your company after reading your homepage? If the answer is no, another technical tweak probably will not change the outcome.
I would make my homepage painfully obvious. This sounds boring, and I think boring wins. If someone lands on your homepage for the first time, they should immediately understand three things: what you are, who you help, and why you are different. Not eventually. Immediately. If a model has to read your pricing page before it understands your category, you have already made the job harder than it needs to be.
I would spend less time publishing and more time reinforcing. The internet does not need another thousand blog posts saying the same thing. It needs more companies consistently reinforcing the same identity. Every page should point in the same direction: homepage, documentation, pricing, about page, founder profile, social profiles, comparison pages, review sites. None of them should tell a different story. Founders underestimate how much confidence comes from repetition. Humans sometimes find repetition boring. Machines find it reassuring.
I would build evidence before I need it. Only a small percentage of companies in the benchmark had meaningful third-party citations, and that is not something you can fix the night before a launch. Evidence compounds. Every interview, podcast, conference talk, guest article, founder sharing your work, and comparison page that includes you gradually creates an external record AI systems can learn from. You cannot manufacture that overnight. You have to earn it.
I would still invest in building an audience. Some readers might think this report suggests social media is not important. That is the opposite of my conclusion. Founders should invest heavily in becoming known, not because ChatGPT rewards follower counts, but because people create evidence. One thoughtful thread can introduce your company to thousands of people, some of whom write newsletters, host podcasts, publish comparison articles, or recommend software to clients. Those secondary effects matter much more than the follower number itself. Attention creates opportunities, opportunities create evidence, and evidence creates confidence. That is the sequence I increasingly believe in.
- 1Rewrite the homepageNot to sound clever. To remove ambiguity.
- 2Pick one category and keep repeating itDo not invent five ways to describe the same product. Choose one and reinforce it everywhere.
- 3Audit every public description of your companyLinkedIn, X, Crunchbase, Product Hunt, founder bios, directories, review sites. Do they all describe the same company?
- 4Create something worth citingOriginal research, benchmarks, experiments, case studies. AI trusts evidence that exists beyond your own claims.
- 5Be patientHomepage clarity can improve in a day. Authority usually cannot. Trust is accumulated, not installed.
When we started AudFlo, I thought the challenge was helping founders optimise for AI. Today I think it is much simpler: help founders become easier to understand. Everything else begins there. The first hundred audits did not give us all the answers. They did something more valuable. They changed the questions we are asking, and I suspect the next hundred will change them again.
What this research does not tell us yet
One thing I have become increasingly uncomfortable with is how confidently people talk about AI visibility. You often see statements like "ChatGPT ranks websites using…" or "Claude rewards…" or "Gemini prefers…". The reality is much messier. These systems change. Models evolve, training data changes, retrieval systems improve, and new sources appear. Anyone claiming to have completely solved AI visibility is probably overestimating what they know, and I certainly do not think we have all the answers. This report is a snapshot, not a conclusion.
There are still questions we cannot answer. The first hundred audits revealed patterns, not every cause. I still do not know exactly how much influence each of these has on recommendation quality: founder reputation, podcasts, YouTube videos, conference talks, GitHub activity, Reddit discussions, Product Hunt launches, Wikidata entities, Wikipedia pages, and review websites. I have opinions, but I would rather collect evidence before turning those opinions into advice.
Honestly, I hope some of the findings in this report become outdated, because that would mean founders are improving: homepage clarity is no longer the biggest issue, more companies are building external authority, and AI is getting better at understanding businesses. Research should evolve. If our benchmark looks identical two years from now, something has gone wrong.
The next thousand audits should answer better questions than the first hundred did. Some of the things we plan to measure include which industries improve fastest over time, whether AI recommendations correlate with stronger entity consistency, which trust signals appear most frequently in highly recommended companies, whether founder branding measurably improves recommendation confidence, and how AI Visibility changes after companies implement AudFlo recommendations. Those are questions I have not seen answered publicly yet, and I think they are worth investigating.
When I started AudFlo, I thought the product would help founders optimise websites for AI. After reviewing the first hundred audits, I think that is only part of the story. The bigger challenge is not optimisation. It is understanding. AI cannot recommend a company it cannot confidently describe, and it cannot confidently describe a company that tells a different story everywhere it appears. The companies that stood out were not necessarily the biggest, the oldest, or the most technically sophisticated. They were simply easier to understand. Maybe that is where AI visibility starts: not with another technical checklist or another ranking factor, but with making it obvious who you are.
Continue your AI visibility journey
If you are curious how your own company compares with the patterns in this report, there are a few places to start.
Run an AudFlo AI Visibility Audit to see how your website scores across AI Visibility, Readiness, and Authority, and compare your results against the benchmark discussed here. To understand how each engine evaluates and references companies, read our guides on getting recommended by ChatGPT, Claude, Gemini, and Perplexity.
One finding from this report is that external evidence matters, and one of the best ways to create it is by consistently sharing useful ideas. If building an audience on X is your current priority, SupaBird's guide to growing from zero to 10,000 followers complements this research by focusing on awareness, while this report focuses on what happens after people discover your company.
This report is based on the first 100 websites audited through AudFlo and represents our observations at the time of publication. We will keep updating these benchmarks as the dataset grows to 500, 1,000, and beyond. Some of these conclusions will undoubtedly change. That is exactly why we will keep measuring.
Key takeaways
- →Across the first 100 audits, the average AI Visibility score was 37/100.
- →The most common recommendation was adding clear category phrasing to the homepage, not fixing schema.
- →Readiness averaged 61 while Authority averaged just 19: companies prepare their own sites but rarely earn outside evidence.
- →Only 8% of audited sites had meaningful third-party citations.
- →AI recommends what it can confidently describe, so clarity and consistency beat clever positioning.
Common questions
FAQ.
How many websites did this research cover?+
What was the average AI Visibility score?+
What was the most common recommendation?+
What is the difference between Readiness and Authority?+
Does growing an audience on X improve AI visibility?+
How many sites had meaningful third-party citations?+
Does this research prove what causes AI recommendations?+
What should a founder do first?+
Continue reading
More from the blog.

AI Visibility
10 Best AI Visibility Tools in 2026 (Compared by a Founder)
A founder-tested look at the platforms that show how AI engines see, cite, and recommend your brand, scored on one consistent framework.

AI Visibility
AI Visibility Score Explained
What the number means, how it is built from four weighted pillars, and how to move it up over time.
See why AI recommends competitors instead of you.
AudFlo is an AI Visibility Audit Platform. Run a free scan to get your AI Visibility Score and the exact fixes that help you get recommended.
New here? Read the complete AI Visibility Guide for founders or browse every article on the blog.
About the author
Matthew Lin
Architect by training. Property developer by profession. Tech entrepreneur by passion.
Founder of AudFlo, an AI Visibility Audit Platform that helps founders understand why ChatGPT recommends competitors instead of them.